人工智能资讯 第18页
聚合当前分类下的最新内容,按时间顺序查看第 18 页精选文章。

亚马逊被问到 AI 手机,Panos Panay 没否认,但重点不是 Fire Phone 复活
Panos Panay 在 Financial Times 采访中没有明确否认亚马逊重做手机,只说目标“不一定是手机”,直接回答 no 虽然准确但会误导。此前传闻称亚马逊在做代号 Transformer 的 Alexa AI 设备,探索过智能手机和 dumbphone 形态,但目前没有发布确认。真正要看的不是 Fire Phone 是否复活,而是亚马逊能不能借 AI 助手重新抢回随身入口。

OpenAI 部分微调 API 退场:微调没死,但不再适合多数团队当默认答案
OpenAI 正在弃用部分 finetuning API,这不是全面取消微调能力,但足够说明微调路线在主流 AI 应用工程里降温。 多数团队该先补长上下文、RAG、工具调用、agent 流程和推理成本账本;顶级应用和开源模型团队,反而还会继续押注后训练。 真正的分水岭不在“会不会微调”,而在数据、评测、部署和成本控制是否跟得上。

AI 圈没大发布,但主战场已经换到工程账本
这期 AI News 表面安静,硬信号却很密:评测继续加难,训练和推理继续降本,Agent 开始补运行时。我的判断是,AI 竞争正在从“谁的模型更大”转向“谁能把评测、成本、运行时和工作流做成系统”。对产品和工程团队来说,下一步不是追每个新榜单,而是重算模型选型、工具链权限和交付成本。

AI 医疗真正的入口,不在模型,在 Medicare 的账单里
美国 CMS 将在 7 月 5 日启动 10 年期 ACCESS 试点,让 150 家机构测试按慢病管理结果付费的新 Medicare 模型。它不是专门为 AI 公司开绿灯,但第一次给诊间之外的 AI 护理、随访和社会支持协调留下了可报销入口。
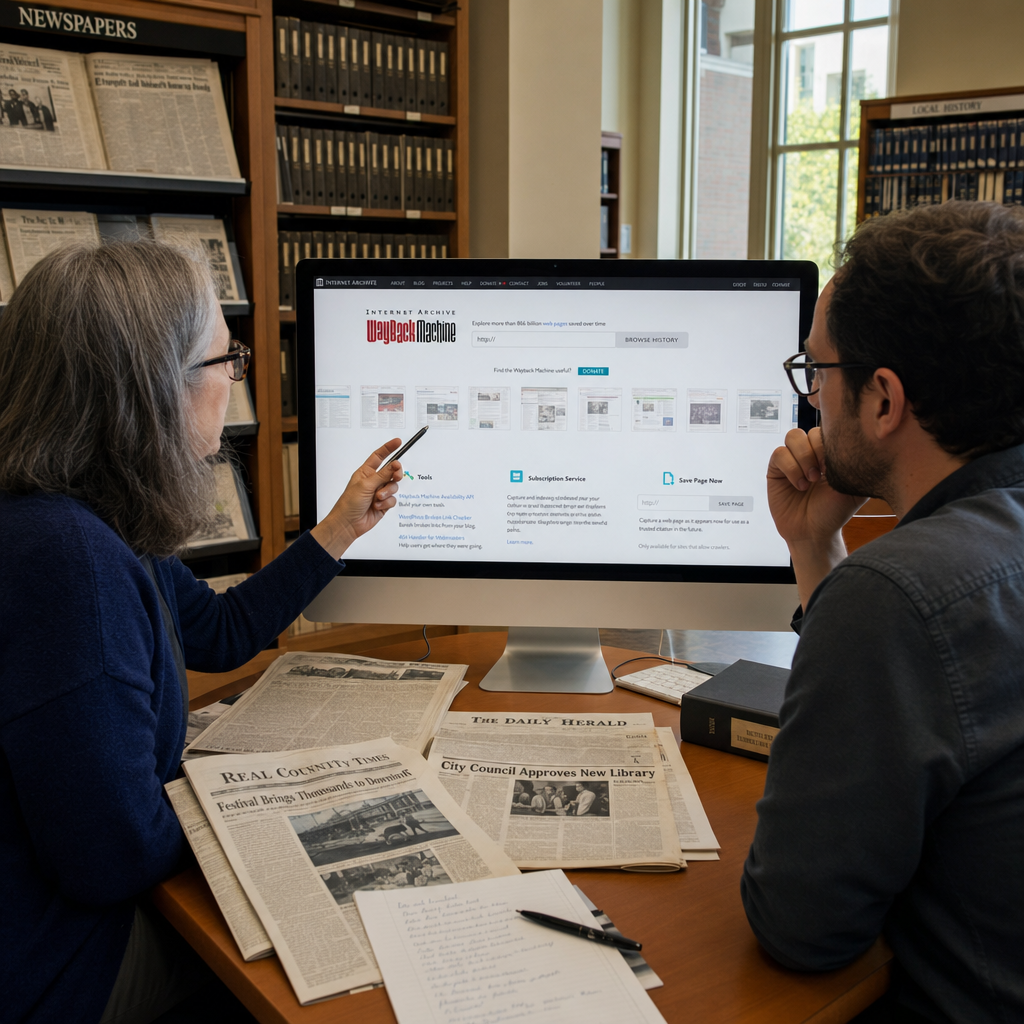
媒体封堵 Wayback Machine:防 AI 抓取,别把新闻档案也一起关掉
数字权益组织 Fight for the Future 发起请愿,要求《纽约时报》、The Atlantic、USA Today 等主要媒体领导层停止阻止 Internet Archive 的 Wayback Machine 存档新闻内容。真正的争议不在于媒体能不能防 AI 抓取,而在于用同一把锁拦住公共存档,可能削弱新闻长期可访问性、事实核查和抗审查能力。

“Ralph Loop”是假的,AI裁员焦虑是真的
Simon Willison 转引的是 Mo Bitar 在 TikTok 上的黑色幽默,不是 AI 方法论,也不是职场建议。虚构的“Ralph Loop”讽刺的是一种真实激励:谁能把“自动化”讲成预算、晋升和裁员理由,谁就可能先占到位置。真正该警惕的不是某个梗,而是企业用模糊 AI KPI 奖励话术投机。

AI 数据中心搬到住宅旁:SPAN 的微型算力实验,省下机房后风险落到谁身上
SPAN 想把搭载 GPU 的 XFRA 微型数据中心放到新建住宅旁,先在 2026 年做 100 户试点,2027 年扩到 8 万个节点、超过 1GW 分布式算力。它瞄准的是 AI 推理、云游戏和流媒体等边缘任务,不是替代大型训练数据中心。真正要看的不是宣传里的低成本,而是电网、合同、安全和居民体验能不能扛住。

AutoScout24 用 Codex 提效:数字很亮,关键不在买工具
AutoScout24 Group 已把 ChatGPT 推给约 2000 名员工,并让 Codex 进入约 1000 名工程、数据和产品人员的日常流程。官方称部分项目周期从 2-3 周缩短到 2-3 天,但这是 select projects,不能外推成全公司十倍提效。真正值得看的是流程:AI 编程工具只有进入 PR review、重构、文档和事故复盘,才可能从演示效率变成组织产能。

NVIDIA用Codex:真正变贵的,是不会治理AI代理的团队
OpenAI发布NVIDIA案例:部分工程与研究团队正在用基于GPT-5.5的Codex做生产系统、内部工具、代码迁移和端到端机器学习实验。材料里的10倍实验提速、最高约20倍效率提升,都来自受访者说法,不是独立评测。真正该看的不是AI写代码快了多少,而是工程组织的试错成本、权限边界和研发节奏正在被重新定价。

Codex 走出代码区:办公室里先被压缩的,还是那层“材料拼装工”
OpenAI 把 Codex 推向数据分析、销售、设计、投资和投行等非开发岗位,新增角色插件、Sites 预览和 annotations。关键变化不在“AI 会写更多东西”,而在它开始接入企业已有工具和流程,压缩办公室里最常见的材料拼装层。真正的门槛也不在演示效果,而在权限、审计、数据隔离和员工是否愿意把关键流程交给它。
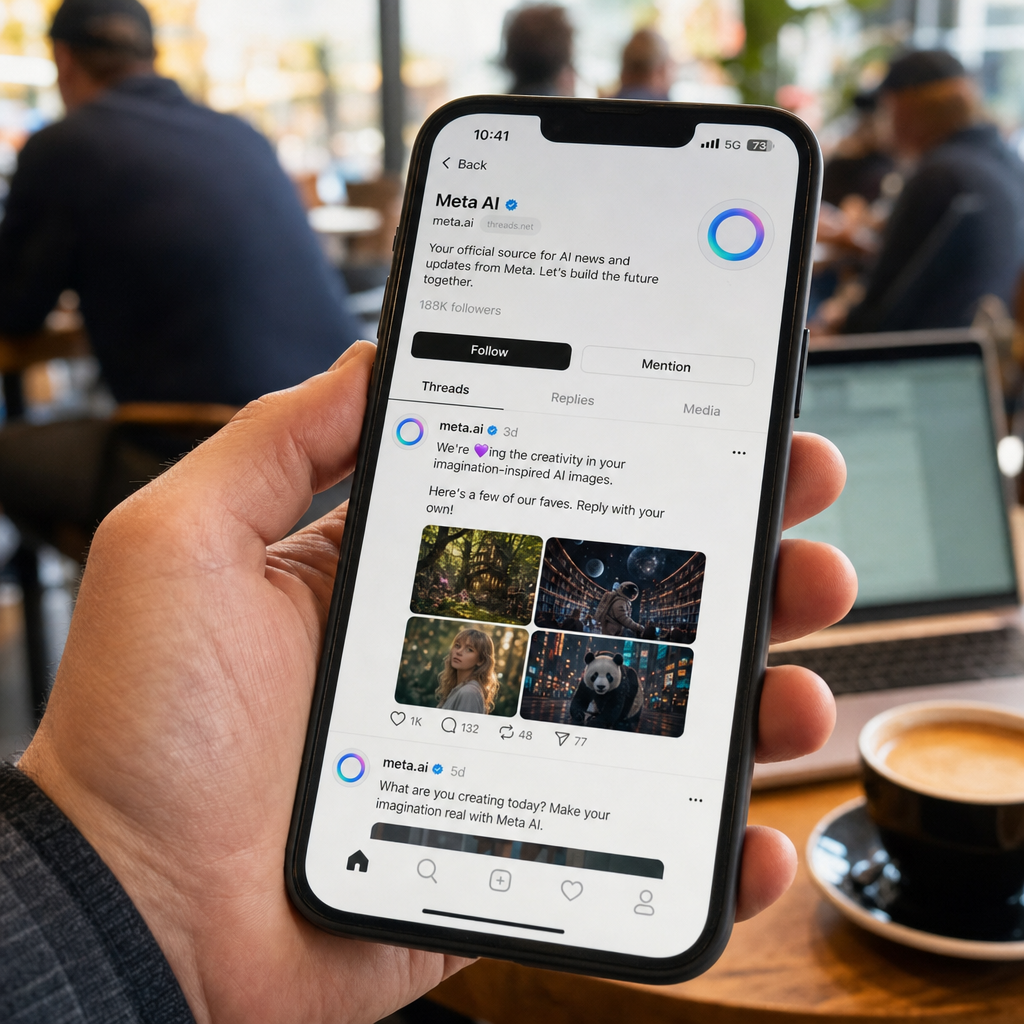
Threads 的 Meta AI 不能屏蔽:真正刺眼的是退出按钮被降级
Meta 正在 Threads 测试一个可被 @ 调用的 Meta AI 账号,测试地区包括阿根廷、马来西亚、墨西哥、沙特和新加坡。争议点不在于它像不像 X 上的 Grok,而在于用户发现它不能像普通账号一样被彻底屏蔽。Meta 给出的静音、隐藏和“不感兴趣”,只能减少出现频率,不能替代 block。

Cactus 开源 2600 万参数 Needle:端侧 AI 的看点不是聊天,是工具调用变小
Cactus Compute 开源 Needle,一个 2600 万参数的单轮函数调用模型,官方称由 Gemini 3.1 蒸馏而来,面向手机、手表、眼镜等小设备。它的价值不在于替代 Qwen、Gemma 这类通用模型,而在于把“选工具、填参数”这一步压到很小。对端侧 AI 团队来说,它更像一个可试的轻量路由器,但真实可用性还要看 schema 适配、微调成本和真机推理表现。

当“看起来懂”比真懂更值钱:AI 正在放大职场里的空洞表达
一篇观点文章批评职业平台正在奖励“看起来懂”的表演型输出:更容易被看见的,常常不是更准确的专业判断,而是更会制造互动的内容。生成式 AI 没有发明这种问题,但它把低成本、像样、可批量复制的空洞表达工业化了。真正受挤压的,是靠作品、验证和责任建立声誉的工程师、写作者、设计师与创作者。

OpenAI 的 16MB 小比赛:AI 代理把研究竞赛变快,也变吵
OpenAI 复盘 Parameter Golf:16MB 产物、8×H100 十分钟训练、固定 FineWeb held-out loss,8 周吸引 1000+ 参与者和 2000+ 提交。最关键的变化不是某个小模型技巧,而是 AI 编码代理几乎成了默认参赛工具。它降低了实验门槛,也放大了复制、噪声、归因和审核成本。

Googlebook 预告的重点不是笔记本,是 Gemini 要抢桌面入口
Google 上线 Googlebook 预告页,时间写到 2026 年秋季,但价格、芯片、屏幕、续航都没给。它真正抛出的不是硬件参数,而是 Gemini 作为 PC 操作入口的设想。Android 重度用户最该看手机联动是否真能进入日常工作流;换机人群现在不必等配置,先等可用性证据。

Google与SpaceX谈轨道数据中心:AI算力想上天,成本账还在地上
《华尔街日报》援引知情人士称,Google与SpaceX正洽谈把数据中心送入轨道;TechCrunch已向两家公司求评。眼下这不是已签协议,也不是SpaceX独家合作。更准确的判断是:轨道数据中心暴露了AI算力的电力、土地和审批压力,但离可采购的商业产能还很远。

Altman 庭上反击 Musk:OpenAI 争的不是道德,是谁能管住先进 AI
Altman 在 Musk 起诉 OpenAI 公司结构案中作证,称 Musk 当年曾考虑让其子女继承一个由他控制的 OpenAI 营利实体;这只是证词,不是法院认定。Musk 一方指控 OpenAI 通过营利子公司背离非营利和安全承诺,Altman 则反驳称 OpenAI 基金会资产规模约 2000 亿美元,并非“偷走慈善”。真正该看的,是先进 AI 能否摆脱强人控制、资本结构和商业激励的同时拉扯。

Google 用自然语言生成 Android 小组件,Gemini 正在挤进主屏
Google 发布 Create My Widget,用户可用自然语言生成可添加、可缩放的 Android 主屏小组件,今夏先登陆最新 Samsung Galaxy 和 Google Pixel 手机。重点不是“写代码”,而是 Gemini 开始接管主屏、输入法、自动填充这些系统入口。对普通用户,短期看它能不能省掉反复打开应用的动作;对 Google,关键看权限边界、数据连接和稳定性。

Android 17 给短视频加了 10 秒刹车,但油门还在平台手里
Google 在 Android 17 中推出 Pause Point:用户打开自己标记为分心的应用前,系统会强制等待 10 秒。它比传统应用计时器更靠前,打断的是启动动作,不是刷完后的懊悔。这个功能有用,但更像平台在成瘾设计、监管压力和用户自控之间做的一次低成本风险转移。

Anthropic把Claude接进律所系统,法律AI竞争开始贴近工作流
Anthropic为Claude for Legal增加法律插件和MCP连接器,覆盖文档检索、审查、判例资源、证词准备和文书起草等事务。它不是新建一个“AI律师平台”,而是在把Claude从聊天框推向律所现有系统。对Harvey、Legora这类垂直法律AI公司,压力会先落在试点入口和外围工作流上,而不是立刻替代其深度交付。

中国开放模型的账本:省钱不在调用,而在少走弯路
Interconnects 讨论中国开放优先的 AI 模型生态,关键不在“开源模型调用更便宜”,而在前沿研发能不能少重复试错。Ai2 OLMo 3 和 Epoch AI 的研究都指向一个判断:前沿模型的大头成本常在研发计算,而不是最后一次正式训练,但比例只能看作区间估计。对企业来说,低迭代场景不必急着迁移;真正受影响的是要做二次训练、工具链和前沿追赶的团队。