人工智能资讯 第2页
聚合当前分类下的最新内容,按时间顺序查看第 2 页精选文章。

NVIDIA 的合成数据实验:造题只是表面,管题才是门槛
NVIDIA 在 Hugging Face 发布 Nemotron 预训练用的 task-seeded 合成 Q&A 数据流程:用公开任务训练集做种子,生成新问题、答案、推理和上下文。它在 Nemotron-3 Nano 的 100B token 继续训练实验中带来部分基准提升,但数学平均基本稳定。真正该看的不是“合成数据有没有用”,而是预训练竞争正在从拼语料规模,转向拼数据结构、验证能力和训练配比。

Endava 把 OpenAI 接进交付流程:软件服务公司的旧算盘松了
Endava 正在把 ChatGPT Enterprise、Codex 和 OpenAI 技术嵌入 DavaFlow,从会议准备、产品发现到软件工程、部署和运营流程都覆盖到。重点不是“企业用了 AI”,而是技术服务公司的交付模式开始从堆人、堆流程,转向人机协同编排。对技术管理者和项目负责人来说,下一步要看的不是账号开了多少,而是需求、治理、协同和激励有没有跟着改。

亚马逊仓库机器人能听人话了,但重点是系统更会管人了
亚马逊发布新一代全自主仓储机器人 Proteus,重点升级是 AI 自然语言交互:员工不再必须用专用软件,可像给同事派活一样下达搬运任务。 新 Proteus 仍在亚马逊实验室试点,计划 2027 年上半年先在欧洲部署;亚马逊称它可走出 dock 区域,在更大仓库范围内搬运容器、衔接工位、辅助配送站点。 这不是“机器人会聊天”的热闹功能,而是仓库调度权继续向系统集中。效率账更清楚,岗位替代和劳动节拍的账还没结完。

伯克利部分 CS 课程挂科上升:AI 没法背全锅,但正在放大基础缺口
UC Berkeley 部分计算机相关课程出现不及格成绩上升,授课教师把它同学生更频繁使用 AI 工具、数学基础变弱联系起来。现在还不能说 AI 直接导致挂科,更稳妥的判断是:AI 让学生更容易跳过训练过程,也让原本的基础能力差距更早暴露。对高校教师和课程设计者来说,难题不是简单禁用 AI,而是重新验证学生到底会不会推理、调试和证明。

大模型“由权重构成”:一篇科幻仿作为什么戳中记忆与责任问题
Max Leiter 的《Weights》是对 Terry Bisson《它们是由肉做成的》的文学仿写,不是技术论文,也不是“大模型已有意识”的声明。它真正刺到人的地方,是把大模型写成“由浮点权重和矩阵乘法构成”的存在,反问我们还能不能用“只是模式匹配”绕开经验、记忆和责任。下一代模型开始加入跨会话记忆后,这个问题已经从科幻玩笑进入产品治理。

Wasmer 两周做出 Edge.js:Codex 是工程杠杆,还是提速叙事
Wasmer 称借助 OpenAI Codex,用两周做出 Edge.js,让 Node.js 工作负载可在 WebAssembly 沙箱和边缘层运行,不依赖 Docker。 这件事的重点不是 AI 多写了几行代码,而是 Codex 被用到架构、查 bug、根因定位和 C++/汇编层调试。 两周、一年、10x 到 20x 都来自 Wasmer 自述。对团队更有用的判断是:先做验证,不要直接把它当成成熟迁移路线。

Ted Chiang反驳AI意识论:Claude会说“我”,不等于它有感受
Ted Chiang在《大西洋月刊》发文,反驳把大语言模型的语言表现当成意识、情感和道德主体的说法。争议焦点不是Anthropic是否宣布Claude有意识,而是它在Claude“constitution”文件和公开表述中使用了大量近似主体的语言。对AI伦理研究者和科技从业者来说,真正要做的是把研究假设、产品说明和用户界面分开,避免把系统行为写成内心生活。

GPT-Rosalind 更新:OpenAI 想进生命科学的实验流程,但硬门槛不是跑分
OpenAI 更新 GPT-Rosalind,把 GPT-5.5 的工具调用、代码能力和生命科学专项能力接入药物化学、基因组学、湿实验排错和科研插件工作流。它现在以 research preview 面向合格机构开放,不是全面商用发布。真正该看的不是 benchmark 涨了多少,而是 AI 正在逼近科研流程中间层;但能不能被审计、复现、追责,仍是硬门槛。

Google Dreambeans:把你的 Gmail、照片和搜索记录,画成每日生活建议
Google Labs 推出实验应用 Dreambeans:经用户授权连接 Gmail、Calendar、Photos、YouTube、搜索历史等数据,每天生成 10 到 14 条 AI 插画故事和生活建议。它目前只面向符合条件的美国 Google AI Ultra 用户,个人 Google 账号可加入等待名单。真正要盯的不是名字怪,而是 Google 正在测试一种新入口:把“了解你”包装成“帮你安排一天”。

Gemma 4 12B:Google 把本地多模态 AI 卡进 16GB 门槛,但别急着吹神机
Google 发布 Gemma 4 12B,主打 16GB 内存或显存设备可本地运行,补上了移动小模型和高端本地模型之间的中档空位。真正的新信息不只是参数规模,而是默认 MTP、多模态编码减重、18GB 权重和 16GB 设备现实压力一起出现:它让本地 AI 更可试,但还没证明自己真好用。

AethexAI 融 300 万美元:语音 AI 的真盲区,不在模型榜单上
AethexAI 获得 300 万美元 pre-seed 融资,4DX Ventures 领投,押注非洲和中东的本地语音 AI。它自建 Kora 小模型和语音编排层,目前日处理超过 1.7 万通电话。真正的看点不是又一家语音 AI 公司融资,而是电话网络、方言、混语、延迟和价格点,正在逼出一套不同于欧美市场的 AI 架构。

Suno 估值 54 亿美元:AI 音乐先跑规模,版权账还悬着
Suno 完成 4 亿美元 D 轮融资,估值升至 54 亿美元;约 7 个月前,它的估值还是 24.5 亿美元。更关键的是,UMG、Sony、GEMA 仍在追诉,Warner 虽已和解并授权,但不能代表行业整体转向。资本押的不是版权风险消失,而是押 Suno 能先做成平台,再把版权账改写成可谈判、可分摊、可定价的成本。
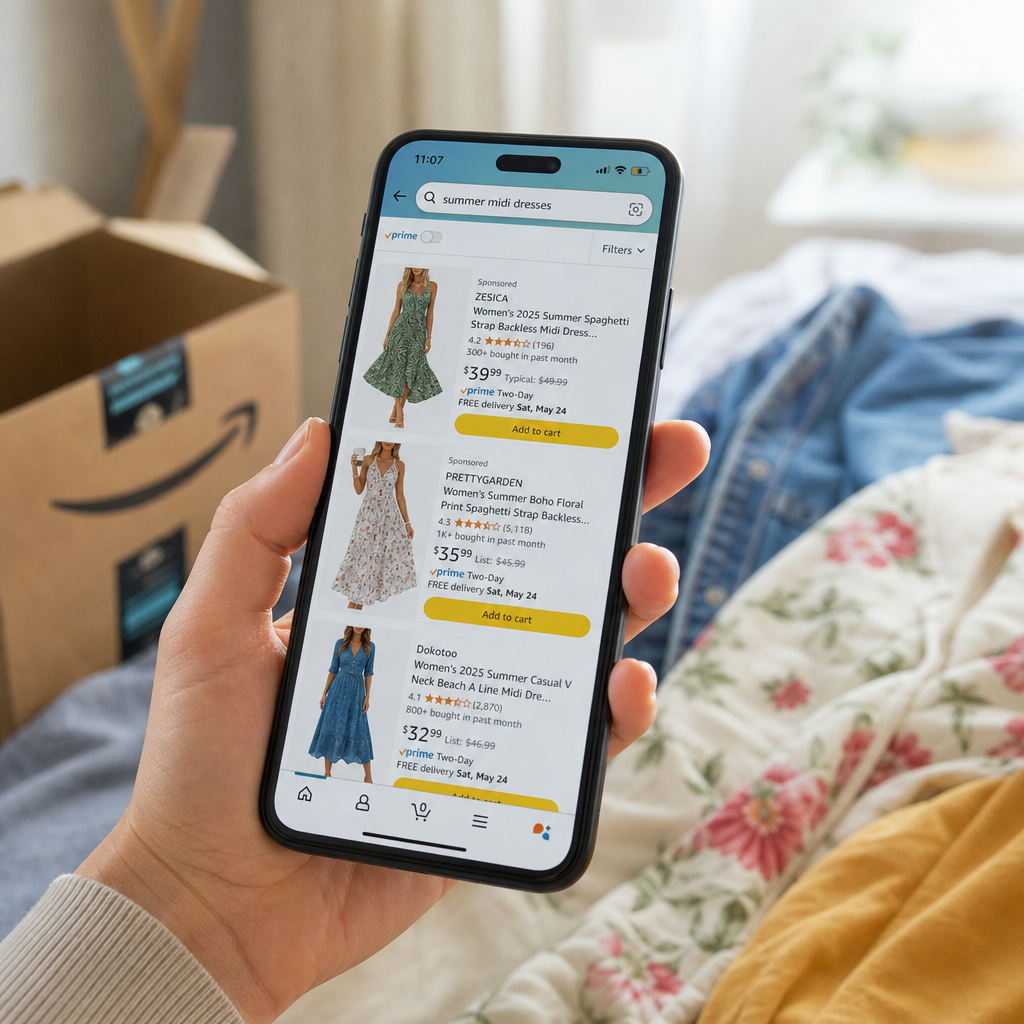
亚马逊搜索栏开始“先造图再找货”:方便背后,是平台在接管你的想象
亚马逊在移动端搜索栏加入生成式 AI 图片:用户描述服装或家居用品后,系统先生成参考图,再搜索相似商品。它解决了“不知道专业名称”的购物痛点,但也把电商搜索从匹配关键词,推向了塑造欲望。

DaVinci Resolve 21:Photo 页面才是 Blackmagic 的真野心
Blackmagic 发布 DaVinci Resolve 21,AI 工具扩到搜索、修脸、语音、救焦点和去模糊,新增 Photo 页面,把静态摄影拉进 Resolve 工作流。 最关键的变化不是功能变多,而是 Resolve 正在侵入 Lightroom、Photoshop、Premiere 组合工作流的边界。 专业剪辑师、调色师和小型制作团队会先受益;摄影师要不要迁移,取决于是否愿意用学习成本和生态绑定换整合效率。
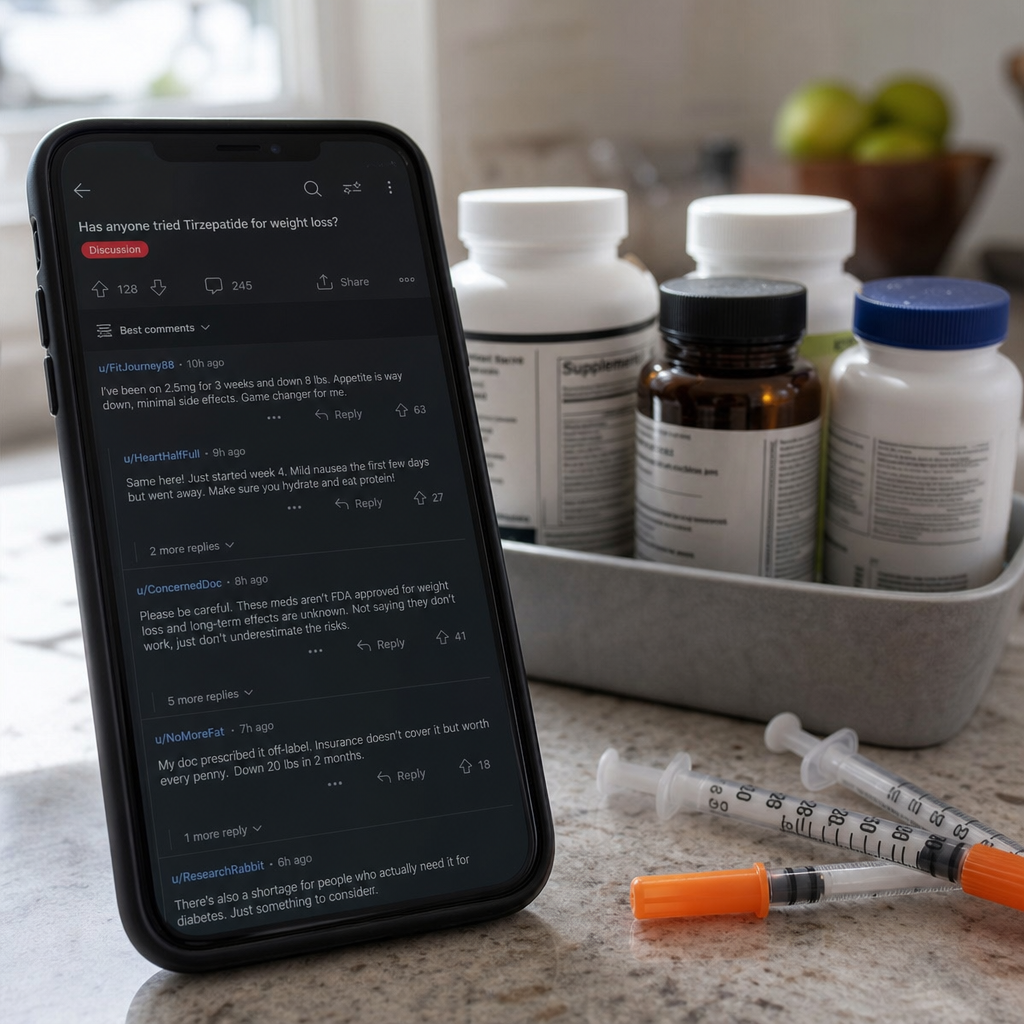
Reddit 被拿来投喂 AI 搜索,健康水军开始换打法了
r/biohackers 版主称,部分肽类和 HRT 相关营销方疑似用养号、机器人和付费真人污染社区讨论,以影响 ChatGPT 和 Google AI 搜索的引用结果。 版主已限制相关新帖,把讨论压到每周 megathread;这说明 Reddit 正从讨论场变成 AI 答案供应链的一环。 健康类 AEO 的风险不止是买错产品,青少年、自我实验者和依赖 AI 搜索查健康建议的人,可能把营销内容误当经验或医嘱。

微软在 Build 亮出自研模型:还牵着 OpenAI,也开始自己下场
微软在 Build 2026 集中发布 MAI-Thinking-1、MDASH、Copilot 超级应用和 OpenClaw 支持,信号很清楚:它不想只做 OpenAI 的云和应用入口。微软仍是 OpenAI 的主要云合作伙伴,但 4 月合同重谈后,双方从深度绑定转向有限合作。真正要验证的是,微软能不能把企业客户和 Windows 生态优势,转成一线模型能力。

DharmaOCR 用 DPO 治 OCR 复读:失败样本别急着删
DharmaOCR 把 DPO 用在巴西葡语结构化文档 OCR 上:先 SFT,再用同一批文档、同一模型生成的好坏候选构造偏好对。结果是在 5 个开源模型家族上,文本退化率相对 SFT 平均下降 59.4%,降幅约 37% 到 88%。 我更在意的不是“DPO 又多一个场景”,而是失败样本的身份变了:它不只是脏数据,也可以是治理生成式模型顽固失效模式的负反馈资产。

Meta Business Agent 全球上线:WhatsApp 正在变成商家的收费工作台
Meta Business Agent 已面向全球 WhatsApp Business 开放,同一机器人也进入 Instagram DM,能回答问题、推荐产品、预约、筛选线索并转人工。收费会进入部分 WhatsApp Business Premium 层级,中大型企业则按 token 用量付费。我的判断是:Meta 真正想拿下的不是客服工单,而是商家每天开工的第一屏。

Meta缩减员工电脑追踪计划:AI训练数据碰上办公室隐私边界
Meta在员工反对后缩减MCI电脑活动追踪计划:每次可暂停数据收集最多30分钟,也可申请完全豁免。MCI会记录员工工作设备上的按键和鼠标点击,用于训练AI模型,Meta称数据不作其他用途,并设有敏感内容保护措施。争议的核心不是一个暂停按钮,而是AI训练开始进入员工日常操作后,谁能决定数据何时被拿走、能否拒绝。

Google AI 搜索在英国补上链接,但出版商还没拿回定价权
英国 CMA 要求 Google 调整 AI Overviews:清楚标注出版商来源、提供访问链接,并允许英国出版商退出 AI 搜索使用,且不得影响普通搜索排名。这个决定没有禁止 AI 搜索,也没有要求 Google 付费,但它把真正的矛盾挑明了:AI 可以总结网页,不能把来源变成看不见的燃料。

蛋白序列很多,真正能用的折叠可能没那么多
Ligo 研究团队在扩展蛋白结构训练数据时发现,自然蛋白序列规模很大,但可复用的折叠结构高度冗余。我的判断是,生物生成模型下一轮竞争不会只看谁折叠更多序列,而会转向谁能更干净地切分结构、去掉噪声、抓住任务相关信号。